Nspawn OpenStack with OpenStack-Ansible


The OpenStack-Ansible project has been around for a few years now but if you're unfamiliar with it, the TL;DR is it's an OpenStack deployment project running OpenStack services within containers and uses Ansible. The original project came from the Rackspace Private Cloud, and when it was started it set out to containerize workloads without jumping on the fail whale tail like everyone else at the time. This project was the basis for production private cloud environments managed by the RCBOPS (Rackspace Cloud Builders and Operations) team. As this team was running real-world workloads on the platform, the project needed to be stable, not a science project, and it needed to provide a high-performance cloud with network isolation, the ability to use block devices for container storage, low-level tunables, upgradable, and general system stability. While the initial release was meeting our needs it, was a large monolithic repository of highly opinionated systems. The team knew we needed a more modular and generally consumable platform. As a testament to the capabilities of the team behind the project and the power of the OSA platform (os-ansible-deployment at that time) the project pivoted to the modular system that we still use today and we did this within two releases (made modular at the time of the Kilo release) all without breaking the upgradability of the project.
Why would we ever want to break away from such an amazing platform?
The OSA project deploys workloads in LXC containers and for the most part it's been great. LXC is super stable, fast, configurable, and capable. So why is this post being written and why would the project ever want to break away from such an amazing platform? Well, as time's ticked by the technology surrounding containers has greatly improved and most of the containerization systems are quite capable these days, especially when comparing them to where they were just a short time ago. Sadly the seemingly endless reams of container run-times and orchestration engines continually being re-invented typically only focus on the model founded by Docker. While this model works for a lot of applications, many of these platforms still won't meet our basic requirements (multiple networks per container, network isolation, file system barriers between the host and container, and system stability). Even if the limitations are overlooked most container run-times still leave a lot to be desired, especially when running a complex system such as OpenStack. All that said, one standout technology nearly everyone is using, and is also producing a container run-time, is systemd. Surprisingly, systemd by itself will meet all of our requirements without additional dependencies while simultaneously opening up a world of capabilities and platform enhancements previously not thought possible.
Unify management of networks, file systems, and containers
At this point, for better or worse, systemd has impacted just about everyone in the wide world of Linux and while it's not loved by everyone, its a fact of life for most. A lot of capability is pre-packaged within systemd but a lot of it is not well understood and even more of it is not being highlighted by many of the mainline distributions. Within systemd one of the many "features" of this init system is the ability to unify management of subsystems like networks, file systems, and containers. The unified framework extends across all distributions of Linux (running systemd) all without adding dependencies or complicating the general operator workflow. After a bit of investigation into systemd and systemd-nspawn I've come to realize that it, by itself, will allow us to meet all of our basic requirements, minimize our installation footprint, speed up deployment times, and unify our tools across all of our supported distributions of Linux (Ubuntu, CentOS, SUSE); this can be done without expanding the scope of the OSA roles which power our deployment capabilities making the new driver a candidate for drop in replacement of our existing LXC stack or even allowing both to run side-by-side.
The remainder of this post will dive into a high-level overview of how we can build the systemd-nspawn driver into an OSA cloud. Each subsection will have a corresponding hands-on blog post going over how each component is being used within the work in progress PR implementing the nspawn driver.
Network Topology
I wanted lower level deployment capabilities while maintaining compatibility
At this point, OSA is fairly well received and has a strong body of deployers within the community. We have a diverse set of core contributors and an even larger body of folks in the channel asking questions while simultaneously helping others out; as the creator of the project, it's amazing to see this happen! So with that in mind, I wanted lower level deployment capabilities while maintaining compatibility with our existing, and well-known stack. The new driver needs to be able to integrate into the stack allowing developers and deployers to try things out without having to learn an entirely new system; it should compliment what folks already know. The driver will need to be able to connect to the basic sets of bridges: (br-mgmt, br-vlan, br-vxlan, br-storage, and br-flat) which has been a basic construct of OSA since it's inception. With systemd-nspawn we're not able to do exactly what we had with LXC and that's due to a limitation which only provides for one bridge and veth-pair per container. This technical limitation means we're not able to exactly follow our existing pattern of bridges and veths however we can use a more advanced and capable network option, macvlan, which can be used multiple times per-container across multiple interfaces.
Example digram(s) for macvlan enabled containers
Simple Network Overview
This is a basic idea of what we need to get up and running to allow systemd-nspawn containers to connect to our known set of interfaces and bridges.
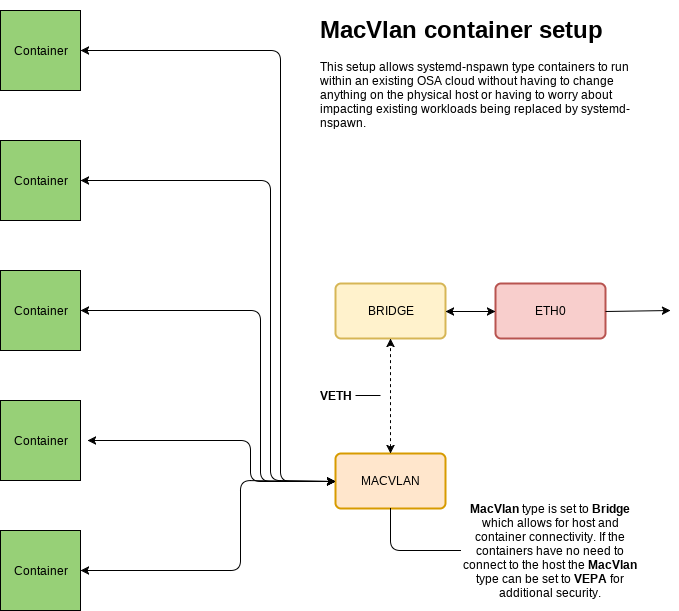
Compatible Network Overview
So with this basic configuration in mind, we can expand on it to allow multiple containers to communicate with isolated networks using different macvlan interfaces. This gives us the same network capabilities found with the LXC driver but in a more performant and potentially more secure setup. See the ip-link man page for more on available modes.
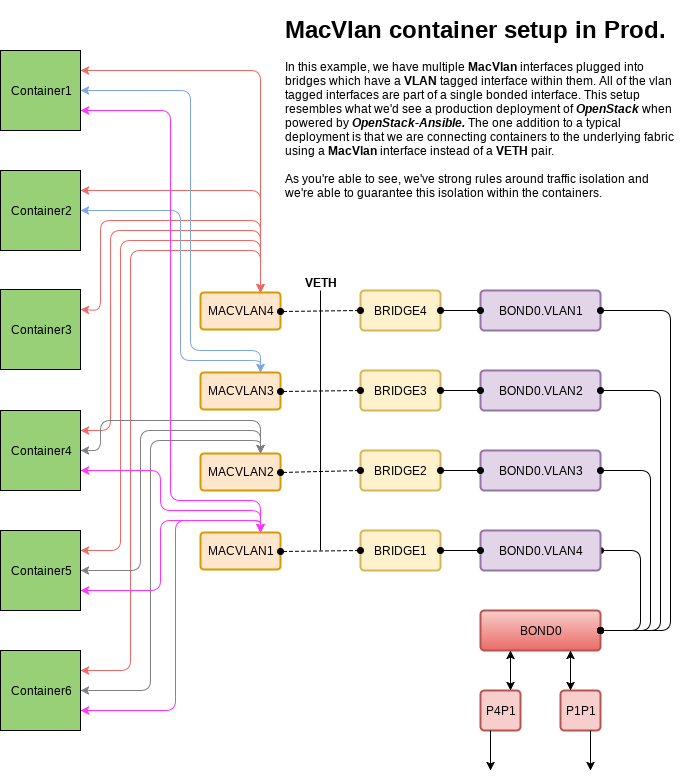
Greenfield Network Overview
The previous topology can be simplified if the deployment is greenfield and there's no need to integrate anything on the host machine with any other legacy network interface.
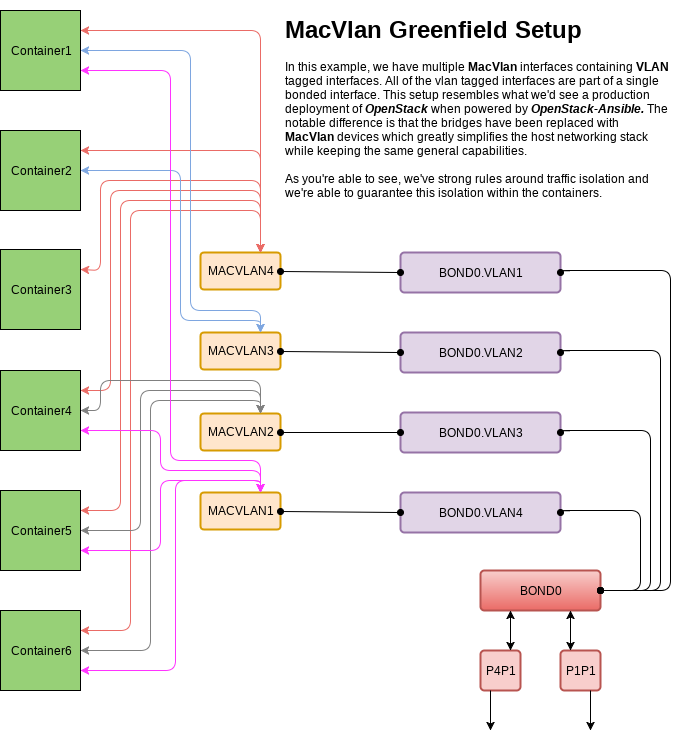
As you can see in these diagrams each container can connect to one or more networks through the use of macvlans and the security constraints of each individual network can be set based on the needs of the deployer. This gives ultimate flexibility to the end-user, builds on a well-known architecture, and meets our need for deployment system by providing isolated networks.
You can find the functional post for host network configuration here
Storage Layout
Within LXC we had three different storage options though only one met the needs of our production-ready deployment system, logical volumes. The requirement for LVM was really so that we had file-system barriers between the containers and the physical host. While commonly overlooked, having a file-system barrier between the containers and the host machines makes a real difference in terms of stability and security. While I won't be going into the specifics of file-system barriers I would recommend reading up on the Importance of Write Barriers which provides some good insight on why we're using them by default.
In considering a new containerization technology I wanted to ensure we meet our minimum requirements. With systemd-nspawn we're able to run our containers from a BTRFS subvolume which not only provides us containers located on a block device, fencing them away from the host, it also allows us to minimize our container footprint by provisioning workloads into BTRFS subvolumes. This capability is built into machinectl and requires no additional complexity or automation to leverage. We can clone images into place using the built-in tooling and spawn new containers from existing ones within fractions of a second.
using BTRFS and subvolumes the storage footprint is less than 1.84GiB in total
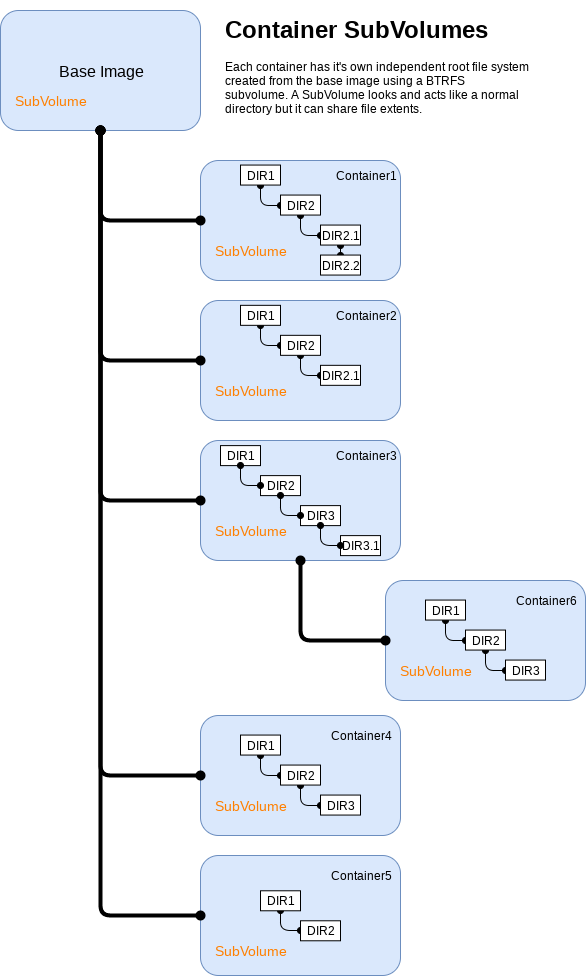
As for why running our workloads from subvolumes is important, take the example of an OSA All-in-One where we have roughly ~32 containers provisioned on a single host. Typically, with LXC, we see about 1GiB of initial storage used per-container after its been provisioned. Each container then has an expected run rate of about 10GiB. However, when provisioning the same workload with systemd-nspawn using BTRFS and subvolumes the storage footprint is less than 1.84GiB in total (spawned from a base image which is about 761.21MiB). After running an AIO for about two weeks the run-rate of the systemd-nspawn containers was about 16GiB and that was without any additional bind-mounts for persistent storage which had not been implemented in the work In progress driver at that time.
The flexibility in storage doesn't end with the subvolume story. The BTRFS block device can either be simple (provided automatically by systemd) or rigid consuming a physical device. As it's assumed most servers will be leveraging volume groups and logical volumes it makes sense operators may want to use some of their extents to build containers within a constrained storage pool. While I recommend this, it's optional. Provisioning a logical volume, formatting it BTRFS and mounting it over /var/lib/machines further limits the potential impact container workloads could have on a physical host machine and gives container storage strong boundaries. If no physical block device is used for container storage systemd will create a loopback file-system, format it BTRFS, and mount it at /var/lib/machines. Either back-end works well, provides the same feature set, and exceeds our requirement for file-system barriers between containers and the host machine; it's all a matter of preference.
Get more information on storage backend options here
Container Provisioning
Container provisioning is the most simple aspect of the entire nspawn driver
Container provisioning is really a matter of creating a new subvolume which is taken care of through the use of the machinectl CLI utility with the clone argument by providing the base image name and the target image name. The base image can be any root file-system you desire. For my tests I used the Ubuntu Xenial Cloud RootFS but I could have just run debootstrap --arch=amd64 xenial /var/lib/machines/xenial-base to build my base image. The machinectl CLI utility has an argument named pull-tar which can download any tarball available on the network. Once the image is on disk we create a simple systemd unit file which represents the container. This means a "target image name" has to be the same as the "unit file name". Finally, we reload the daemon, enable the service and start the container.
Container provisioning is the most simple aspect of the entire nspawn driver. Each container is nothing more than a subvolume and a unit file which is entirely managed through systemd. Managing our containers uses the same process as managing a service, we simply invoke systemctl and pass in the verb needed for a particular action. Example:
systemctl status systemd-nspawn@container1.service
● systemd-nspawn@container1.service - Container container1
Loaded: loaded (/lib/systemd/system/systemd-nspawn@.service; disabled; vendor preset: enabled)
Active: active (running) since Tue 2017-06-27 05:01:46 UTC; 14h ago
Docs: man:systemd-nspawn(1)
Main PID: 9335 (systemd-nspawn)
Status: "Container running."
Tasks: 36 (limit: 8192)
Memory: 281.9M
CPU: 1min 26.969s
CGroup: /machine.slice/systemd-nspawn@container1.service
...
This same information can be obtained using the machinectl command with the status argument and the container name.
A simple example of manual container provisioning can be found here and all of the available configuration options for nspawn can be found here. In order to attach our containers to our multiple networks, we define the Network section in our nspawn configuration file and provide a space-separated list of all of the macvlan type networks we wish to attach to the container using the "MACVLAN" option. These networks will then be directly translated into interfaces within the container with the "mv-" prefix. So, if the macvlan interface on the host is named "mth1" the interface within the container will be "mv-mth1". This is extremely convenient as we'll be able to programmatically know the names of the interfaces before the container is provisioned.
Nspawn allows us to use both machine and application containers at the same time while also meeting our basic requirements
Another capability that we'll have, which is unique to OSA and enabled through systemd-nspawn, is the ability to run both machine and applications containers with the same unified tool chain. As stated, OSA, by default, uses LXC which creates a Virtual machine like container which is "bootable". Because our default is a machine type container we need the ability to provision containers that manage more than one process and come with an init system; this is sometimes called a "fat" container. Machine containers gives us access to general system tools for debugging and troubleshooting which allows us to build roles that target both bare-metal and containers without having different code paths. However, as we adopt nspawn we'll enable developers to build new roles, new systems, and new container types which leverage the application container pattern if they so choose. There have been times when folks have wanted to follow the application container model but were unable to due to how LXC works out of the box and how OSA was deploying services. With the addition of the systemd-nspawn we'll no longer be limited to a single container and application delivery type. Nspawn allows us to use both machine and application containers at the same time while also meeting our basic requirements (multiple networks per container, network isolation, file system barriers between the host and container, and system stability). The lower level control we get from systemd, it's present level of maturity giving us a stable interfaces/systems, and the flexibility we'll get from systemd-nspawn enable some amazing possibilities.
See how you can spawn containers here
TL;BRF (Too long, But you Read this Far)
If you've kept with this post this, I applaud you. There's a lot to cover and even more I've omitted in an effort to keep this blog post concise. To recap, adding systemd-nspawn as a deployment capability will enhance the OpenStack-Ansible project giving us access to new and exciting capabilities while maintaining compatibility with the deployment architecture that has made us successful.
Related Posts
- Networkd for nspawn with OpenStack-Ansible
- Machinectl Image Management
- Storage Setup for Machinectl
- Rocket Past The White Whale & Spawn Containers
This is just the beginning
I hope this overview of what is being worked on within the OSA project has been insightful and inspires conversation in the #openstack-ansible channel on freenode or on twitter; I'd love to get feedback on the proposal, the mission, and how folks might leverage such a driver should it become mainstream. You can see the work in progress PR implementing the nspawn driver here.